Pytorch - 基于循环神经网络的正弦函数预测模型训练与检测
小白劝退预告
- 仅简单介绍思路,没有用作教程的打算,如果读者没有机器学习基础、循环神经网络基础或Pytorch基础 —— 会很不友好的(
Pytorch实现神经网络
Pytorch 准备正弦函数数据集
其中超参数的含义如下:
1. input_size: 输入预测的特征值数目
2. output_size: 最终输出的预测数值数目
3. hidden_size: 循环神经元的特征数目
4. batch_size: 一次训练批量数目
5. num_hidden: 循环层神经元的层数
6. length_num: 数据集的数据数目
1 | input_size = 1 |
训练数据集展示如下:
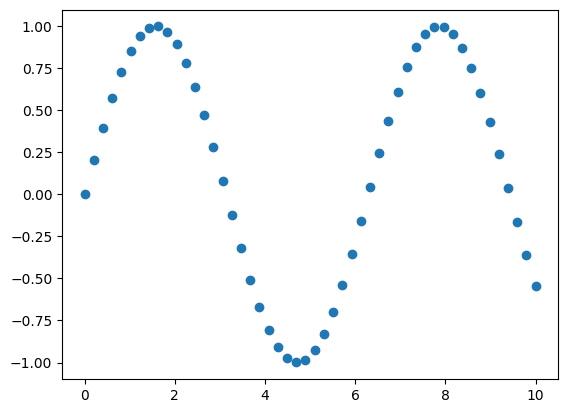
Pytorch 实现循环神经网路
用 torch.nn.Module 来自定义模型,模型不必太复杂,一个循环节点和一个多层感知机就足够了
一定要留意各神经元间张量格式的衔接!!!
1 | import torch |
定义超参数
超参数就是全局变量,我们需要定义以下几个超参数:
- model: 要训练的模型,实例化上文我们定义的类即可
- Step: 训练步数,共 6000 次
- learning_rate: 学习率,控制着模型训练速率的常数
- criterion: 损失函数,本质为 torch.nn 对象,对于多分类的模型,我们采用平方损失函数(即 MSELoss )
- optimizer: 模型优化器,本质为 torch.optim 对象,在本次训练中,我们选择 Adam 作为我们模型的优化方法
1 | net = RNN() |
实现检测
这个函数用于可视化我们的模型预测结果如何
我们先输入一个初始值,我们的模型会预测出第二个值
我们再把第二个值交付给模型,模型会给出第三个值,以此类推直到 49 个预测值全部给出
最后通过 plt 将数据可视化
1 | def test(hidden_back): |
Pytorch 实现训练过程
我们将模型的训练过程整合成为一个函数,这个函数接受三个输入
我们拆分这个训练过程,它主要由这几步构成:
- 每次训练,将训练的函数数据和隐藏层数据放进模型
- 通过模型计算得到结果,存进 outputs 里,并通过损失函数得到损失值 loss
- 先清空模型的参数梯度设置,调用 loss 的反向传播重新计算梯度,并依据梯度对模型参数赋值
- 每 1000 次训练,计算这轮计算的时间、损失值、正确率,用作训练时的日志输出
1 | def train(Step, test_step, hidden): |
代码总览
1 | import torch |
最终,这个模型在训练 6,000 次训练后的预测结果如下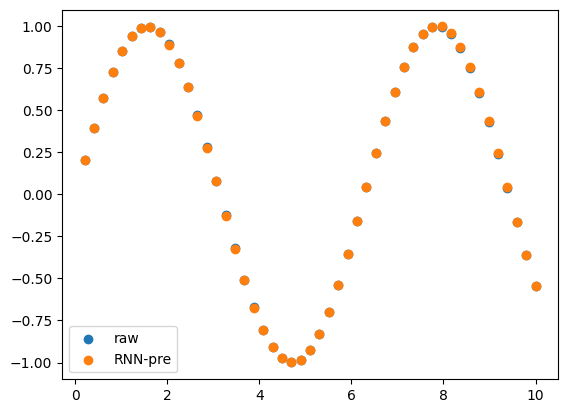
最终检查测试的可视化
本博客所有文章除特别声明外,均采用 CC BY-NC-SA 4.0 许可协议。转载请注明来自 Tokisakix's Blog!
 wechat
wechat